In previous posts, we started with basic neural network architectures (multilayer perceptrons) and then continued with specialized architectures for image recognition and object classification (convolutional networks), sequence learning (recurrent networks), and speech recognition (bidirectional RNNs and LSTM networks). In the past two years, the success of deep learning has prompted more study into other problems that neural networks can solve – and the network architectures that can solve those problems.
In the next several blog posts, we'll look at neural network architectures for neural computing. Rather than learning how to answer some question directly (such as object classification or digit recognition) these neural machines can learn algorithms.
This post will introduce neural random-access machines (NRAM), a type of neural machine first described in a conference paper at ICLR 2016 by Kurach et al. In the next post, we'll implement the NRAM model using Theano.
Register-Only NRAM Architecture
Instead of immediately jumping to the full NRAM architecture, we'll build up to it gradually, starting with a simpler version of the NRAM architecture. This architecture should still be capable of learning simple algorithms; it differs from NRAM in that it has a much more limited memory. Our network would be able to learn and compute expressions involving simple arithmetic, comparisons, and conditionals, such as
$$f(x, y, z) = \begin{cases} 2 x + z & \text{if } x = y \\ \max(y, z) & \text{otherwise} \end{cases}\\ g(x, y, z, w) = \begin{cases} x + y + z + w & \text{if } x = y \\ w - x & \text{if } w = \min(x, y) \\ z & \text{otherwise} \end{cases}$$
Crucially, however, our network will not perform these operations itself, but will rather control an auxiliary machine to do it. While formulating our network as a controller may seem more complex than necessary, it enables us to do two things:
- Perform integer arithmetic. Since neural architectures must be fully differentiable to be trainable via backpropagation, the only functions that can be learned are continuous ones. However, most algorithms are not differentiable, and so we must have a separate system from the neural network perform the main computation.
- Upgrade our machine piece-by-piece. By delegating part of the logic to a network-external system, we can increase the computational capability of the network by adding new capabilities to the external system without redesigning or drastically increasing the size of the network. This can provide us with a large boost in expressivity with a fairly limited increase in the number of parameters and the training time required. We'll see this flexibility in action later in this post!
Machine Overview
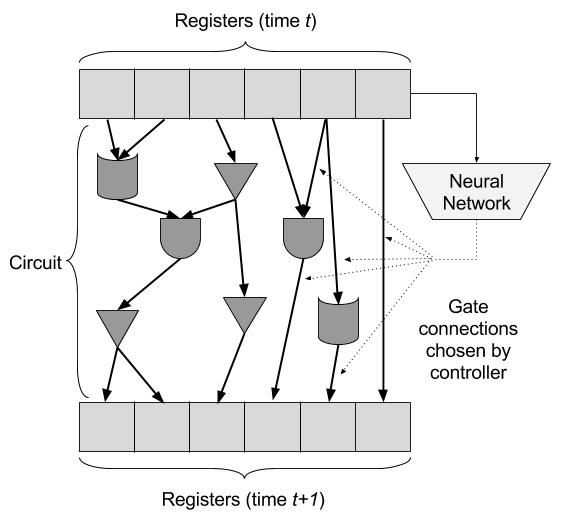
Our machine will consist of three main pieces: registers, gates, and the controller. The registers form the data storage space for the machine, the gates will perform computation on the registers, and the controller will direct the gates to control what computation they do. At each timestep, the controller will choose how to wire the registers and gates together, creating a neural circuit, and the outputs of circuit will be written back to the registers. In this way, complex expressions can be computed, since the controller can choose different gates and operations on the registers at every timestep.
The primary challenge presented by this design is that of differentiability. Recall that neural networks are trained by formulating a cost function that captures how well the network is doing, differentiating that cost function with respect to the network parameters, and then using an optimization algorithm (such as gradient descent) to find appropriate network parameters. For this to work, we must be able to differentiate the result of the neural network with respect to its parameters.
However, if in our machine the gates perform logical operations and integer arithmetic, and the registers store integers, how can this entire system be end-to-end differentiable, a requirement for backpropagation training? This, in my opinion, is the most interesting part of the NRAM paper.
Instead of registers storing integers, registers will store probability distributions over integers. Similarly, gates will be lifted to operate on probability distributions over integers, respecting the original operation the gate implemented. The controller will, at each necessary point, select a linear combination of probability distributions that the gates should operate on.
While unintuitive, this transformation is enough to make the entire model end-to-end differentiable.
Operating on Probability Distributions
Next, we'll work through the concrete details of our model, and from this we'll be able to observe that the result is end-to-end differentiable. The role of each of the pieces (registers, gates, and controller) will be addressed in turn.
Registers
$\renewcommand{\R}[0]{\mathbb{R}} \renewcommand{\Z}[0]{\mathbb{Z}} \newcommand{\bmatr}[1] {\begin{bmatrix} #1 \end{bmatrix}}$ Our model starts with $R$ registers, $r_1, r_2, \ldots, r_R$. Instead of holding integers, each of these registers holds a probability distribution over the integers; since we must store the probability distribution, we must choose some fixed maximum integer we can work with. If we denote the maximum representable integer $M-1$, and the set of representable integers be $\Z_M = \{0, 1, \ldots, M - 1\}$, then each of our registers is a probability distribution over $\Z_M$, which can be represented as a vector $r_i \in \R^M$, such that the components of each $r_i$ are non-negative and sum to one.
In this representation, the integer two would be represented via its one-hot encoding as $$2 \to \bmatr{0 \\ 0 \\ 1 \\ 0 \\ \vdots \\ 0} \in \Z_M.$$
Gates
In addition to our $R$ registers, we have a list of $Q$ values, $f_1, f_2, \ldots, f_Q$, where each value is either a binary function $f_i : \Z_M \times \Z_M \to \Z_M$, unary function $f_i : \Z_M \to \Z_M$, or a constant $f_i \in \Z_M$. These values can include arithmetic operations, logical operations, and useful constants, such as
$$\begin{align*}\text{ADD}(x, y) &= x + y \\ \text{MAX}(x, y) &= \max(x, y) \\ \text{EQZ}(x) &= \begin{cases} 1 & \text{if } x = 0 \\ 0 & \text{otherwise}\end{cases} \\ \text{ZERO} &= 0 \end{align*}$$
Each value $f_i$ can be turned into a module $m_i$, which corresponds to the same function or constant, but lifted to operate on probability distributions instead of on integers (in the case of functions) or to be probability distributions (in the case of constants). For example, the constant ZERO can be represented as a probability distribution over $\Z_M$, where the probability of zero is one and the probability of all other values is zero:
$$m_{\text{ZERO}} = \bmatr{1 \\ 0 \\ 0 \\ \vdots \\ 0}\; ; \; m_{\text{ZERO}} \in \R^M$$
A unary function, such as EQZ, can be converted into a module $m_{\text{EQZ}} : \R^M \to \R^M$:
$$m_{\text{EQZ}}(\vec A) = \bmatr{A_0 \\ 1 - A_0 \\ 0 \\ \vdots \\ 0}.$$
We define $m_{\text{EQZ}}$ in such a manner because the probability that $x$ is zero is stored in its first component $x_0$, and the probability that it is nonzero is the sum of all the other components, or $1 - x_0$.
The same generalization can be applied to any integer functions; in the general case of a binary function $f_i$, the probability of the output being a particular integer $\ell$ is the sum of the probabilities of all the cases in which the inputs produce an output of $\ell$. Thus, we can write the module $m_i$ as
$$m_i(\vec A, \vec B)_\ell = \sum_{0 \le j, k < M} A_j B_k [f_i(j, k) = \ell],$$
where $\ell \in \Z_M$ is the component of the output probability distribution and $[f_i(j, k) = \ell]$ is an indicator function equal to one when $f_i(j, k) = \ell$ and zero otherwise.
In case this is not clear, consider the example of ADD. Following from the equation above,
$$m_{\text{ADD}}(\vec A, \vec B)_\ell = \sum_{0 \le j, k < M} A_j B_k [j + k = \ell].$$
This is needlessly complicated, however, because we know the cases in which $j+k = \ell$; namely, if integer addition wraps around, this only happens when $j \equiv \ell - k \mod M$. Armed with this fact, we can rewrite the above to a simpler and more computationally efficient
$$m_{\text{ADD}}(\vec A, \vec B)_\ell = \sum_{j=0}^{M-1} A_j B_{\ell - k \text{ mod } M}.$$
Controller
In the overview, we said that the controller chooses which gates and operations to perform by wiring the registers and gates together, feeding registers as inputs into gates, as well as the outputs of gates as inputs to other gates. However, doing so in a discrete manner wouldn't work, for the same reason as always: discrete operations cannot be trained via backpropagation.
Instead, the controller chooses, for every gate input, a linear combination of registers and previous gates. As long as the coefficients of the linear combination are non-negative and sum to one (a weighted average), the inputs to the gates will still be probability distributions, and so the gates described above will work.
Specifically, let $o_1, o_2, \ldots, o_Q$ be the outputs of modules $m_1, m_2, \ldots, m_Q$, respectively. Let $\vec a_i$ and $\vec b_i$ be the outputs of the controller (column vectors where each element is the weight assigned to some previous register or gate output). The inputs to module $m_i$, then, are $A$ and $B$ (if the module is binary) defined by $$\begin{align*} A &= \bmatr{r_1 & r_2 & \cdots & r_R & o_1 & o_2 & \cdots & o_{i - 1}} \vec a_i \\ B &= \bmatr{r_1 & r_2 & \cdots & r_R & o_1 & o_2 & \cdots & o_{i - 1}} \vec b_i, \end{align*}$$ where $\vec a_i$ and $\vec b_i$ are outputs of the controller. (In order to ensure that the components of $\vec a_i$ and $\vec b_i$ add up to one, so that $A$ and $B$ are valid probability distributions, the final layer of the controller is a softmax layer.) If the module is unary, then only $A$ is used, and if the module is a constant, then no controller outputs are necessary for it. The list of modules is ordered, so each module can only access the outputs of modules that preceed it in the list.
For example, if there are three registers and three gates (ADD, ZERO, EQZ), then $\vec a_2$ will be the vector of coefficients for the 3rd gate (EQZ), and will have five weights in it (three for registers, one for ADD output, one for ZERO output); the input to EQZ will be the weighted combination of those five distributions (3 registers, 2 gates).
Similarly, the controller chooses a weighted average of old register values and gate outputs as the values to be written to the registers after every time step. The new values written to the registers at the end of the timestep are $$r_i' = \bmatr{r_1 & r_2 & \cdots & r_R & o_1 & o_2 & \cdots & o_Q} \vec c_i,$$ where once more $\vec c_i$ is a softmax output of the controller.
The inputs to the controller will come from the registers. Instead of providing the entire register vector to the controller, only the first component will be provided – the component that corresponds to the probability of the register being zero. This prevents the controller from trying to learn the algorithms itself, instead forcing it to rely on the circuits it generates. Since the controller is only provided the first component, it must use every register just as a boolean value, and decide what to do based on that; this functionality is the decision-making and branching part of the machine.
Cost Function for Training
To use this register-based machine once it is trained, we will initialize the registers with the inputs to the algorithm. Then we will run the system forward timestep-by-timestep until it produces the desired output. Unlike sequence-to-sequence learning, though, our system has no natural "end". Thus, we have two choices:
- Run the system for a fixed and constant number of timesteps $T$, and train it to produce the result we want at the end.
- Train the system to decide, on its own, when it is done.
The authors of the NRAM paper chose to do the second, and so we'll do the same.
During training, the system is still run for a fixed $T$ timesteps. However, in addition to outputting $\vec a_i$, $\vec b_i$, and $\vec c_i$ described above, the controller will output a $f_t \in \R$ at every timestep $t$, which is the willingness to complete at that timestep. This willingness to complete represents the probability that the controller would like to terminate after this step.
Given this willingness to complete, the probability that the algorithm completes at timestep $t$ will be
$$p_t = f_t \prod_{i=1}^{t-1} (1 - f_i),$$
since it is the probability that the algorithm finishes at this timestep $(f_t)$ times the probability that the algorithm has not yet completed $(\displaystyle\prod_{i=1}^{t-1} 1 - f_i)$. In addition, since probabilities must sum to one, at the last timestep $T$ $p_T$ is chosen such that the sum of all the $p_i$s sums to one: $$p_T = 1 - \sum_{t=1}^{T-1} p_t.$$ $p_T$ is not chosen by the network, which forces the network to complete its algorithm in at most $T$ timesteps.
The objective function we use to train our system is a variant on the standard binary cross-entropy objective function. The cost is the negative log likelihood of the correct output in the registers at every timestep:
$$J(\theta) = -\sum_{t = 1}^T p_t \sum_{i=1}^R \log(r^{(t)}_{i,y_i}),$$ where $r^{(t)}_{i,y_i}$ is the probability of register $i$ having value $y_i$ at timestep $t$ (the $y_i$th component at time $t$) and $y \in {\Z_M}^R$ is the vector of desired integer outputs at the end of the algorithm.
The error accumulated at each timestep is weighted by $p_t$, which means that unless the network outputs a high probability of completion, it will not be penalized. Since $p_T$ is not chosen by the network, the error at the last timestep will be high unless the network completes its task earlier.
Introducing Random-Access Memory
Although our register-based machine can learn simple algorithms, those algorithms are quite limited – they can only use as much memory as there are registers. If we add registers, we must also add corresponding weights to the neural network and retrain it; it does not generalize to larger memory sizes.
To address this we can add a variable-sized memory bank. This memory bank $\mathcal{M}$ will consist of $M$ integer values (where $M$ is also the number of representable integers); that is, $\mathcal{M} \in \R^{M \times M}$, since each value in the memory bank is again a distribution over integers.
Since the memory bank has $M$ cells, and each integer in our system can have one of $M$ values, we can interpret these values as pointers to locations in the memory bank. We can then use these pointers to read and write from the memory bank through two new gates.
The first of these, the READ gate, will take a pointer $\ell$, and read the value stored at that location in the memory bank. Since the pointer is a probability distribution, the result will be the weighted average of the values at all the cells in the memory bank, weighted by the probability masses:
$$\text{READ}(\ell) = \sum_{i=0}^{M-1} \ell_i \mathcal{M}_i,$$ where $\mathcal{M}_i \in \R^M$ is the value stored at cell $i$ of the memory bank.
The second gate, the WRITE gate, will take a pointer $\ell$ and a value $v$, and write the value to the location indicated by the pointer. Again, the pointer is a probability distribution, so the gate will write a little bit of the value to each location in the memory bank, as indicated by the probability mass. For consistency, the gate will output the value it writes, but it will also modify the memory bank; if we have a gate $\text{WRITE}(\ell, v)$, the values in the memory bank will be
$$\mathcal{M}_i' = (1 - \ell_i) \mathcal{M}_i + \ell_i v,$$ where $\mathcal{M}_i'$ is the new value in cell $i$ after the gate operation completes. Thus, if the probability mass $\ell_i$ associated with cell $i$ is zero, then the value will stay exactly the same as in the previous step; if $\ell_i = 1$, then the value will be completely overwritten with the new value $v$.
Finally, we can reformulate our cost in terms of the memory rather than the registers while keeping the structure roughly the same:
$$J(\theta) = -\sum_{t = 1}^T p_t \sum_{i=0}^{M-1} \log(\mathcal{M}^{(t)}_{i,y_i}),$$ where $y_i$ is the value that should be stored in cell $i$ at completion of the algorithm. The only change to this cost function as opposed to the previous one is that it accesses the memory bank, rather than the registers; other than that it is identical.
With these two gates and modified cost function, we achieve something very interesting: namely, our neural network is completely independent of $M$. We can change the maximum representable integer without having to create a new set of parameters and retrain our network. As noted in the intro, this flexibility is part of the power of formulating this as a neural network controller – without changing the network or increasing its complexity itself, we added two gates, and in doing so completely changed the set of problems our machine could handle.
With random-access memory, our machine should be able to handle algorithmic problems, such as copying elements in an array, searching through a list of values, or traversing a search tree stored in memory. The original publication tries several tasks, and finds that for simple tasks (reversing an array), the machine can perform perfectly, but for more complex tasks it does make some mistakes (such as in list merging or walking a binary search tree).
In the next post, we'll use Theano to implement this machine, and we'll teach it a few simple algorithms.