Efficient WaveRNN: Optimizing Nonlinearities
Implementing efficient nonlinearities for WaveRNN CPU inference is tricky but critical.
Implementing efficient nonlinearities for WaveRNN CPU inference is tricky but critical.
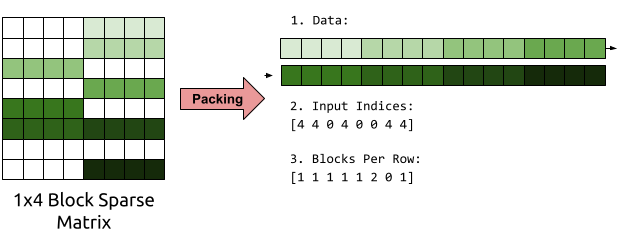
WaveRNN inference can be accelerated by using block-sparse weight matrices combined with specialized block-sparse matrix-vector multiplication kernels.
WaveRNN inference can be made dramatically faster with SIMD inference kernels and int16 quantization.
If implemented in Python and Pytorch, WaveRNN inference is too slow, but we can make it faster with several simple optimizations.
Discretizing audio samples to 8 bits each during WaveRNN inferences introduces significant quantization noise, which we can reduce using µ-law companding and pre-emphasis.
WaveRNN is an autoregressive neural vocoder, a neural network based process for converting low-dimensional acoustic features into an audio waveform by predicting the next sample in a stream of samples. Specialized compute kernels are necessary to make WaveRNN inference fast.