Efficient WaveRNN: Optimizing Nonlinearities
Implementing efficient nonlinearities for WaveRNN CPU inference is tricky but critical.
Discretizing audio samples to 8 bits each during WaveRNN inferences introduces significant quantization noise, which we can reduce using µ-law companding and pre-emphasis.
In this series of posts, we're going to go through the WaveRNN neural vocoder for audio waveform synthesis, along with a variety of implementation details and commonly used extensions. For a real implementation, check out the gibiansky/wavernn repository.
Posts in the Series:
As we discussed in our introductory post, our WaveRNN represents audio using an 8-bit quantization, with each audio sample being stored as an integer between 0 and 255. Since audio is a continuous-valued signal (usually stored with 16 or 24 bits per sample), quantizing it into 256 different values causes audible degradation. The quantization noise is effectively uniform noise added to the signal, distributed evenly across the different frequencies as you can see below.
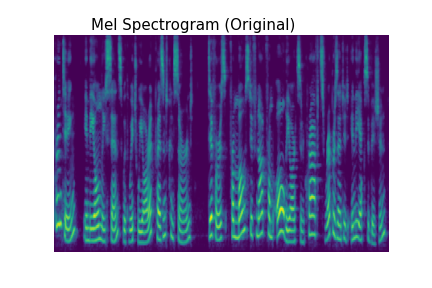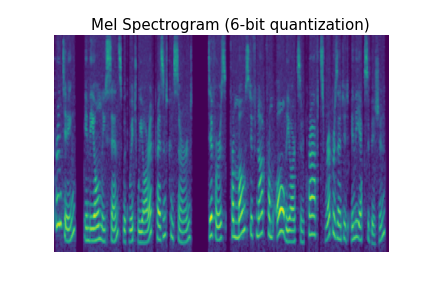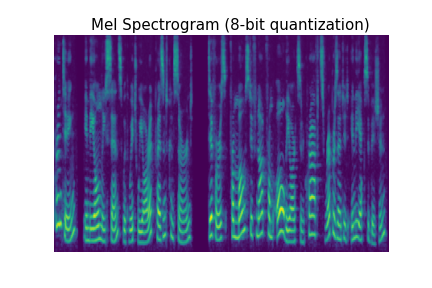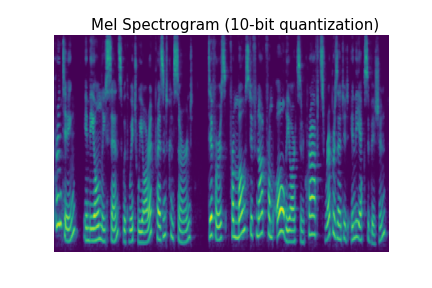
In addition to being easily visible in a spectrogram, you can hear the quantization noise in the audio samples below. (All audio samples in this blog post are based on the first sample in the LJ Speech dataset by Keith Ito.) With 5-bit quantization, you'll be able to easily hear the noise with laptop speakers, but as you get closer to 10-bit quantization, you'll need high volume or headphones to hear it clearly.
OriginalThe simple quantization we demonstrated in the spectrograms and audio clips above was done by splitting the audio range (-1, 1) uniformly into segments, with each segment covering an equal part of the audio range.
Part of the reason that the quantization noise is so audible, though, is that human hearing is sensitive to audio on a wide range of volume scales. (This is why the unit used to measure audio volume, decibels, is a logarithmic scale!) Thus, one approach to reducing quantization noise is to instead apply a non-uniform quantization, where the audio range near zero is quantized with much more detail than the range far from zero.
This non-uniform quantization is done by applying a transformation called µ-law companding prior to quantization. For a signal $x$, the companded signal $\hat x$ is
$$\hat x = \text{sgn}(x) \frac{\ln(1+ \mu |x|)}{\ln(1+\mu)}~~~~-1 \leq x \leq 1$$
When listening to the audio, the inverse operation (µ-law expanding) is done after dequantizing. The resulting audio, as you can see below for a variety of different quantization levels, sounds better – although you can still hear the effects of quantization noise as a subtle background buzz, even with 8-bit quantization.
5-bit Quantization, No CompandingTo reduce the quantization noise even further, we'll apply another operation, pre-emphasis, prior to µ-law companding. (Correspondingly, the inverse operation, de-emphasis, is applied after µ-law expanding in order to listen to the audio.)
Quantization noise is effectively uniform noise, and thus has an equal power across the entire frequency spectrum. However, human perception of pitch is not linear, but rather logarithmic. For example, a pitch difference of 100 Hz is much more perceptible you are comparing 100 Hz to 200 Hz than if you are comparing 10 kHz to 10.1 kHz. The Mel scale is a logarithmic scale meant to emulate human hearing; pitches equally distant on the Mel scale are perceived by people to be equally distant. Because human perception of pitch is logarithmic, and quantization noise is equal across frequencies, human perception of quantization noise is primarily driven by high frequency quantization noise.
Thus, to reduce perceptible quantization noise, we can boost high frequencies using a pre-emphasis filter prior to quantization and attenuate those same frequencies using a de-emphasis filter after dequantization. This will leave the speech content (primarily in the lower frequencies) unaffected and will reduce the power of the added quantization noise in the higher frequencies (since the quantization noise is added right before high frequencies are attenuated).
To apply pre-emphasis, replace a signal $x[t]$ with $y[t]$ as defined by
$$y[t] = x[t] - \alpha x[t - 1].$$
$\alpha$ is a value between 0 and 1, frequently around 0.9 or 0.95 for audio applications.
For the sake of intuition, you can consider what this filter would do to a fixed or low frequency signal and what it would do to a quickly varying signal. If the signal is constant or slowly varying ($x[t] \approx x[t-1]$), then this reduces to approximately $(1 - \alpha)x[t]$, effectively attenuating it by $1 - \alpha$. If the signal is quickly varying, then $y[t]$ will have a high magnitude (little attenuation). (If you are of a more analytical bent, you can compute the frequency response of this filter by taking the Fourier transform of $y[t]$ and evaluating the resulting magnitude as a function of frequency – you will find that attenuation is minimal at the Nyquist frequency of half your sampling rate.)
You can observe the effect of pre-emphasis visually in the log mel spectrograms below. As you increase $\alpha$ and the strength of the pre-emphasis, the lower frequencies are attenuated and the higher ones become dominant.
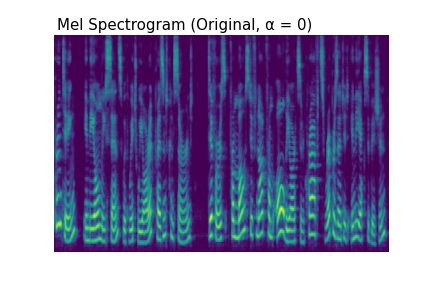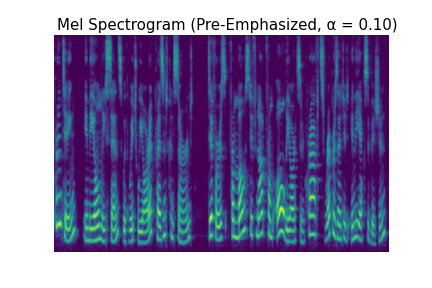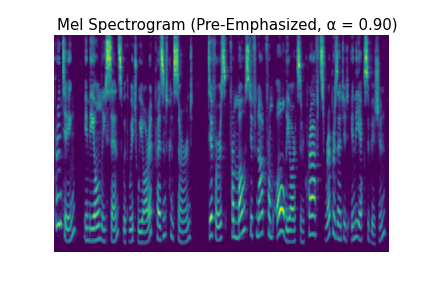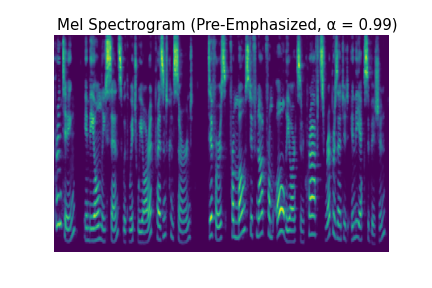
You can also hear the effects of pre-emphasis in the audio clips below.
OriginalTo undo pre-emphasis by applying de-emphasis, compute $x[t]$ from $y[t]$ via the autoregressive equation
$$x[i] = y[i] + \alpha x[i-1].$$
The effects of pre-emphasis can be heard below. In these examples, the audio is pre-emphasized, companded (with µ = 255), quantized (8 bits), dequantized, expanded, and then de-emphasized.
OriginalAs you can hear above, µ-law companding and pre-emphasis can be used to reduce the effect of quantization noise in audio. In order to model audio with WaveRNN, we have to quantize it to 8 bits (though 9 or 10 is also feasible), so that our final layer softmax outputs can have a reasonable dimension (256 for 8 bits, 512 or 1024 for 9 or 10 bits). In order to synthesize clean audio with WaveRNN, we can train our WaveRNN to produce audio which has been pre-emphasized and µ-law companded. To generate the final real-valued audio clip from the WaveRNN-generated integers, we dequantize, µ-law expand, and then de-emphasize the audio.
To recap, when training WaveRNN we:
When synthesizing with WaveRNN, we:
This allows us to model high-fidelity audio with only an 8-bit output.
Our discrete-valued WaveRNN requires our audio to be quantized to an 8-bit representation. Naive quantization introduces a significant amount of noise, known as quantization noise. µ-law companding and pre-emphasis are two transformations we can apply to our signal prior to quantization in order to reduce the impact of quantization noise. If you apply pre-emphasis and companding to the input audio, you need to apply expanding and de-emphasis to the synthesized audio prior to listening to it. Together, these two transformations allow us to model high-fidelity audio with only 8 bits.
Check out the implementation at gibiansky/wavernn or proceed to the subsequent blog posts: