IPython, as many of you may already know, is a set of frontends to the Python language and ecosystem which provides powerful interactive shells, inline data visualization, support for GUI toolkits, as well as a beautiful browser-based notebook interface and a number of other nifty features. In particular, I've found that the notebook interface with its inline documentation and easy re-evaluation is incredibly helpful for development and debugging. As I started working more and more with Haskell, I began to miss the notebook interface. Luckily, IPython was designed from the start to be polymorphic in the language being used: it specifies a protocol and requires a language interpreting backend (which it calls a "kernel") which speaks that protocol. So, I set about creating a language kernel for Haskell, which I have creatively dubbed IHaskell. Along the way, I found that the documentation for how I should go about creating this backend was rather sparse, so in this blog post I'd like to rectify that.
Before continuing, I'd like to reiterate that this is all regurgitating information found elsewhere on the internet in a hopefully useful manner. You may find the complete IPython messaging protocol and this StackOverflow question useful as well.
Note: The links and information in this post are meant to provide a general overview. Specifics of the protocols and API have changed since this was written (for IPython 2.x protocol), so make sure to carefully read the documentation of the protocols. The general picture remains the same, so most of the description in this post are still accurate.
IPython Architecture
IPython is designed for a very flexible configuration. Not only do the frontend and language kernel communicate entirely asynchronously, but the design allows for multiple frontends talking to the same kernel. Although with the advent of the multi-user notebook this may become a reality, in my own use I have always had a single frontend interacting with a single kernel, so I will stick to that for now. Note that making a kernel work with multiple frontends does require more work than just a single frontend, and the details are all in the complete messaging spec (see above). That said, we can picture the basic IPython communication system as follows:
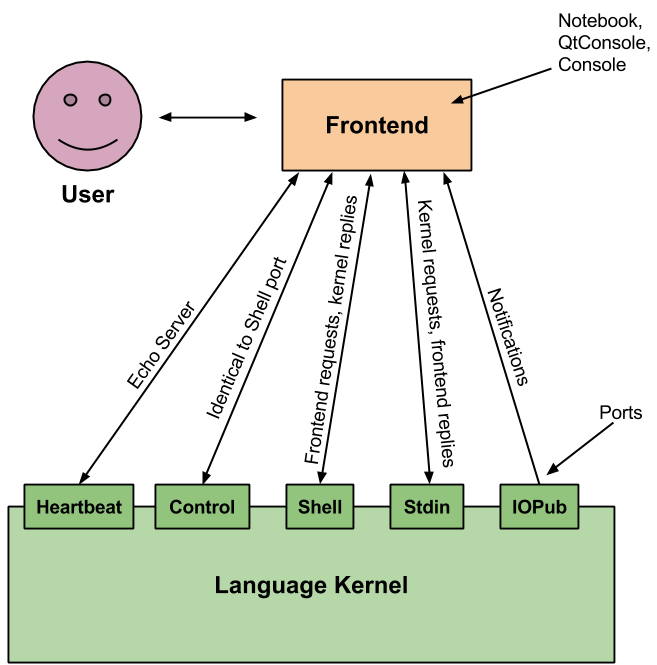
I'm going to refer to these quite often, so keep this diagram handy.
IPython communicates with its kernel backends using the ZeroMQ networking and concurrency library. Luckily, bindings to ZeroMQ exist for most languages, so using it should cause no trouble.
ZeroMQ
ZeroMQ allows you to establish generalized sockets for communication. Although the word 'socket' usually connotes networking, ZeroMQ sockets are slightly more general and are used as a communication and concurrency primitive. When creating the socket, it can be declared as a TCP, UDP, or even in-process socket which does not do any networking.
In addition to the method of transportation (TCP, UDP, IPC, and so on), each socket has a type which indicates how the socket communicates and what type of sockets it can communicate with. Although ZeroMQ defines a number of socket types in order to support very distributed and fault tolerant applications, the ones we are interested in are as follows:
- REP: The only thing this socket does is receive requests and then reply to them.
- REQ: This socket is the opposite of REP - it sends requests and reads replies to them.
- PUB: This socket broadcasts (publishes) information to anyone who is listening.
- SUB: This socket subscribes to a PUB socket and listens to all its broadcasts.
- ROUTER: This socket can be used as a multi-user REP socket. It can receive requests from many other sockets and reply to all of them. ROUTER sockets store the identity of the source of the message before sending the message to the application, and the application receives messages from all origins. When replying to a message, the ROUTER socket will send the reply to the origin of the request.
- DEALER: This socket allows round-robin communication between sets of sockets. If a message is sent to a DEALER, the DEALER will send to all connected peers. This allows sets of sockets to communicate without explicit knowledge of all the sockets in the set.
Kernel Sockets
Although ZeroMQ is capable of much more, we are interested only in the sockets that we'll need for communicating with the IPython frontend. The backend should have the following ZeroMQ sockets:
- Heartbeat: This is a REP socket which simply echoes anything its given. IPython uses this to check up on the kernel - if the heartbeat port does not respond within a few seconds, IPython assumes the kernel is dead and restarts it (or exits with an error).
- Shell, Control: These two ROUTER sockets - which, as far as I can tell, are identical for the purpose of single frontend use - are what IPython uses to query the language backend. Requests for code evaluation, object inspection, and so on are sent through these sockets, and each request must have a corresponding reply.
- Stdin: This ROUTER socket is a socket which the language backend can use to query the frontend for input. For instance, in Python, when
raw_input()is used, the Python language backend requests input from the frontend. - IOPub: This PUB socket is used to publish all code output. When a block of code finishes (or partially finishes) running, messages are sent to all subscribed frontends via this socket, so they can display the output. All output is sent via this mechanism - the reply messages on the Shell messages are very simple and only indicate success and failure.
Configuring IPython
We've now covered all the fundamental ideas behind the IPython communication framework, but before diving in to the messaging details, let's go over getting IPython set up to talk to your kernel. A language kernel should define its own IPython profile. When started with this profile, IPython will know to communicate with the particular language kernel instead of defaulting to the Python backend. In addition, other language-specific configuration (such as initialization, extensions, etc) can be added to this profile. You can create the profile via the shell commands
# Create the profile.
ipython profile create language-name
# Start IPython with the profile.
ipython console --profile language-nameOnce you've created the profile, you can edit the profile configuration to set the kernel. This will be located in your IPython configuration directory, which is going to be ~/.config/ipython or ~/.ipython, depending on your operating system. You will likely want to edit profile_language-name/ipython-config.py. In order to set the language kernel, use the following code:
# Set the kernel command.
c = get_config()
c.KernelManager.kernel_cmd = ["/path/to/executable/kernel_exe",
"{connection_file}"]
# Disable authentication.
c.Session.key = b''
c.Session.keyfile = b'' With this configuration, your kernel will be called with a single command line parameter. This command line parameter will be a JSON file that looks like this:
{
"stdin_port": 48691,
"ip": "127.0.0.1",
"control_port": 44808,
"hb_port": 49691,
"signature_scheme": "hmac-sha256",
"key": "",
"shell_port": 40544,
"transport": "tcp",
"iopub_port": 43462
}This scheme defines the ports, IP, transport mechanism, and authentication mechanism that the kernel should use for communicating with the frontend. The kernel should then create sockets for each of those ports and bind them to the appropriate locations. (Note 'bind', as opposed to 'connect' - in ZeroMQ, there's a difference.)
Reading Messages
Once IPython is attempting to connect to your kernel and you have sockets listening to the correct ports, you can begin parsing and replying to the messages IPython sends your kernel. There are one to two dozen different messages which are all described in the Messaging Protocol. However, only some of them need to be implemented for a useful kernel.
Each message (except for those on the heartbeat port) is serialized as a stream of binary blobs. Quoting the messaging protocol:
[
b'u-u-i-d', # Zmq identity(ies)
b'<IDS|MSG>', # delimiter
b'baddad42', # HMAC signature
b'{header}', # Serialized header dict
b'{parent_header}', # Serialized parent header dict
b'{metadata}', # Serialized metadata dict
b'{content}', # Serialized content dict
b'blob', # extra raw data buffer(s)
...
]The dictionaries are simply serialized JSON, and can be read as such.
If you are reading directly from ZeroMQ sockets, there are several small things to note:
- In order to read the ZeroMQ identities, read all the blobs until the identifier delimiter, "<IDS|MSG>". This will be in several messages if there are several ZeroMQ identities involved, but most of the time this will be a single UUID followed by a "<IDS|MSG>" message.
- The UUIDs are often used for comparison. For instance, the parent header UUID may be used by IPython to determine which message or which notebook is being replied to. However, IPython uses direct string comparison for UUID comparison, so "f47ac10b-58cc-4372-a567-0e02b2c3d479" and "F47AC10B58CC4372A5670E02B2C3D479" will be different, although they represent the same UUID. In addition, IPython console and IPython notebook will use differently formatted UUIDs (console uses the former version, while notebook uses the capitalized latter version). Anyway, be careful to always return the same UUID in the parent that you get in the request - parsing the UUID and later converting it back to a string may not work with all IPython frontends.
Important Messages
For a basic language kernel, you must respond to two message types. The first of these is "kernel_info_request". A kernel_info_request message has no content, but indicates that a "kernel_info_reply" message should be sent back. The kernel_info_reply message will contain information about the kernel, such as the IPython version expected, the protocol version, the language, and so on. This message must be sent before the IPython frontend finishes its initialization, and full detail about what should go into these messages can be found here.
The second and most important message type is "execute_request". An execute_request messages indicates a request to evaluate a block of code. Note that this is not necessarily a single line of code - although the console will only send a single line, notebook interfaces may send significantly more. The full content of the message is available here.
An "execute_reply" message must eventually be sent in reply to the execute_request. The only two fields are the execution counter (so that the frontend knows which execute_request is being replied to) and the status of the execution, which is either "ok", "error", or "abort". The execute_reply indicates that the processing of the source code has been completed and that it has been executed.
Note that the execute_reply message doesn't contain any information about the code that was just run! All information about the code and its output is sent in separate messages on the IOPub port.
Publishing Output
When your language kernel receives an execute_request, it needs to send back an execute_reply as well as several messages on the IOPub port.
Before beginning the execution of the code, send a status update to the frontend declaring that the kernel is busy. This status message informs the frontend that the kernel is currently busy, so that it can potentially display that information to the user. Similarly, when code is done executing, you should send another status update, this time informing the frontend that the kernel is now idle.
During code execution, there are two types of data your kernel may want to send to the frontend. The display data message message, display_data, allows you to publish multiple representations of your data. For instance, if your code outputs a table, it may do so simultaneously as printed monospace code, HTML, Latex, or even a PNG or SVG containing an image of the table. The kernel will then decide the optimal way to display your data, which can lead to beatiful presentations in the IPython notebook.
However, you will likely also want to publish raw output, such as the output from print statements or their equivalent. Although you could do this in the display_data messages, you should instead use the simpler output message pyout. The Python output message indicates that this is the raw output data and not just a representation of some data, and this output data is generally presented differently in IPython frontends.
Further Development
This describes a very basic IPython language kernel. However, there are many other messages required for full capability - things such as object introspection, looking up documentation, and so on. You can figure these out by thoroughly reading the messaging protocol.
If you'd like to read a reference implementation in Haskell, I urge you to look at (and, if you'd like to, contribute to) the development of IHaskell - an IPython kernel for Haskell.